[Data Mining] Linear Regression
이번 포스팅부터 조금 Data Mining스러워진다. 재밌어보이는 plot도 많이 나올 거고 수식도 많이 나올 거다. 그리고 여기서부터는 python code가 조금씩 나올수도 있다. 사실 이 블로그는 애초에 IT 블로그였고, 기본적으로 컴퓨터를 공부하는 사람을 대상으로 쓰고 있었기에 python code가 나오는 것이 사실 이상한 것은 아니다. 그래도 글의 논리 자체가 python code에 너무 취중해있지는 않을 것이기 때문에(python은 오로지 실험용) 컴퓨터 비전공자들도 읽을만 할 거라고 생각한다.
아무튼 linear regression 시작해보자. 우선, linear라는 말이 무엇인지 알아보자. 직선이다 직선. 곡선이 아니라 직선이다. 예전에 linear algebra 포스팅할 때도 linear의 개념에 대해서 이야기했었다. linear는 아무튼 직선이다. linear 하다 라는 말은 직선이다~ 그런말이다.
Regression은 회귀라고 우리 말로 번역이 되는데, 사실 회귀라고 해도 무슨 말인지 잘 모른다. 수학에서 regression은 x와 y와의 관계를 나타내는 선. 이런 개념으로 쓰이나보다. 따라서 linear regression analysis는 x와 y와의 관계를 직선으로 나타내어 분석을 하는 방법이다.
우선 아래의 sample data를 보자.

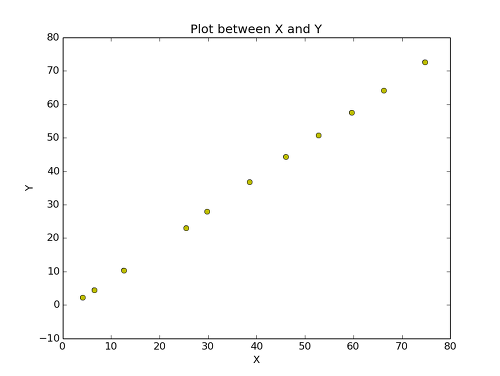
data가 위의 그래프처럼 분포가 되어있다. 대충 보니까, x가 증가하니까 y도 증가한다. 대체적으로 그렇다. 그러면 대충 선을 하나 그어보자.
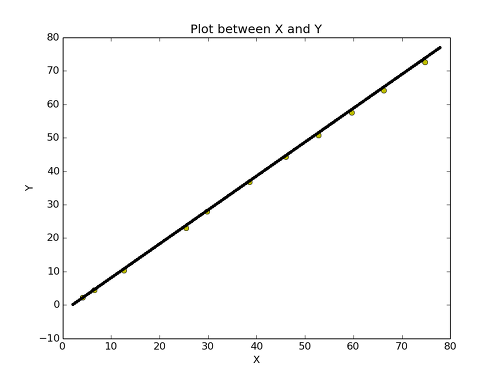
얼추 맞는 것 처럼 보인다. 그런데 이 선은 직선이니까, y = a + bx의 형태로 나타낼 수가 있다. 그러면 이와 같이 분포가 되어있는 모든 data들에 대해서 y = a + bx라는 식을 나타낼 수 있다면 얼마나 좋을까? 그것이 바로 linear regression analysis이다.
그러면 여기서 새로운 용어 하나를 이야기해보자. best-fit. 옷 입을 때, fitting room이라고 하고 fit이 좋다 라고 한다. 그 때의 fit이다. 최고로 잘 맞아 떨어지는 linear line이라는 뜻이다. 그래서 우리는 y = a + bx라는 best-fit을 구하는 공식을 생각해보려고 한다.
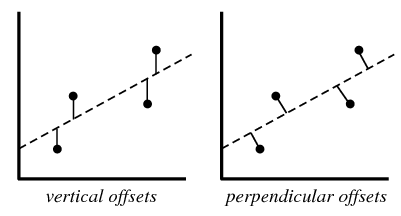
그림 참고: http://mathworld.wolfram.com/LeastSquaresFitting.html
best-fit을 구하는 가장 기본 원리는 위의 그림에서 d의 합을 최소한으로 하는 방법을 찾는 것이다. d는 vertical offset을 이용하여 구하는 방법과 perpendicular offset을 이용하여 구하는 방법이 있는데, 보통 vertical offset이 더 많이 쓰인다. 왜냐하면 그것이 보통 더 정확하다고 한다. 그래서 이 포스팅에서도 vertical offset을 이용하려한다. d를 구하는 공식은 아래와 같다.
d = real y data - expected y data
= real y data - (a + bx) (because, expected y data = a + bx)
여기서 d를 distance의 약자로 d로 써놨는데, 사실 이는 쉽게 설명하기 위함이다. 원래는 이 것을 error(차이)의 e나 residual의 R로 표현한다. 앞으로는 R로 표현하겠다. 아무튼 이 값은 때로는 양수가 될 수도 있고 음수가 될 수도 있다. 예를 들어, x1, y1을 보자. x1일때의 expected y data는 a + bx1이고 이는 실제 y1보다 크다. 따라서 d는 음수이다. 그런데 x2, y2를 보자. x2일때의 expected y data는 a + bx2이고 이는 실제 y2보다 작다. 따라서 R은 양수이다. R의 합을 최소한으로 구하는 방법을 찾고 싶은데 R이 양수와 음수가 되면 우리가 원하는 값을 찾는데 방해가 된다. 그래서 우린 R을 제곱하여 음수가 될 수 없게 한다.
R^2 = (real y data - expected y data)^2
자 이제 우린 R^2을 몇 개 가지고 있지? data 개수만큼 가지고 있다. n개의 tuple에 대하여 x1부터 xn까지의 data들에 대하여 R^2를 구했으니까 n개 가지고 있다. 이걸 수식으로 나타내면 아래와 같다.

수식 참고 : http://mathworld.wolfram.com/LeastSquaresFitting.html
R^2 수식을 최소한으로 만드는 a와 b를 우리는 찾아야 된다. 그 a와 b는 y = a + bx에서의 a와 b임을 잊지 말자. 아무튼 그 a와 b를 찾으면 우리는 best-fit을 찾게 되는 것이다. 그 최소값을 찾기 위해서 우리는 a와 b에 대하여 편미분을 하여 각각을 0으로 수렴시킨다. (이 부분은 미분적분을 배우지 않은 사람들은 이해하기 힘들 것이므로 미분적분을 배우지 않은 사람들은 젤 밑에 있는 a와 b의 결과만 보고 이해하는 것이 나을 수도 있다.) 이 두 식을 행렬으로 나타내면 아래와 같다
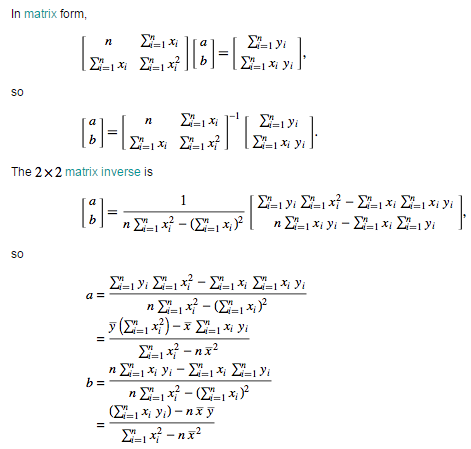
수식 참고 : http://mathworld.wolfram.com/LeastSquaresFitting.html
a와 b를 구하기 위해서 최초의 행렬에 역행렬을 곱하여 a와 b를 유도시켰다. 이 식이 우리가 원하는 a와 b를 구하는 식이다. 이 식을 실제로 젤 위에 있었던 sample data에 적용시켜보자.
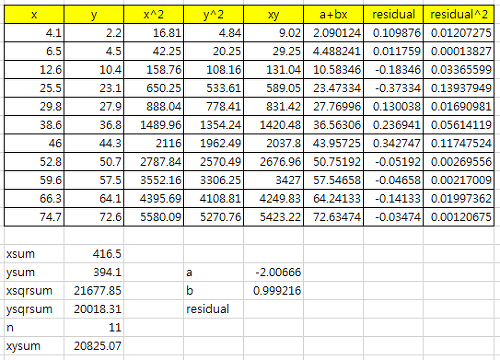
실제로 이렇게 나오는지 python을 통해 확인해보자.

우와 반올림하면 정확히 일치한다. 이제 우리는 x와 y 두개의 데이터를 주면 그것에 대한 a + bx best-fit을 구할 수 있다. 그런데 여기서 궁금한 점이 있다. a + bx가 얼마나 맞는지 평가를 하는 수치를 알고 싶다는 것이다. a + bx가 대충 드러맞는 dataset도 있을 것이고 완벽하게 드러맞는 dataset도 있을 것이다. 그 두 개를 구분하기 위한 평가방법이 있다. correlation coefficient이다. 근본적으로 correlation coefficient를 어떻게 유도하는지를 알고 싶으나, 그 방법은 잘 모르겠으므로 생략하자. correlation coefficient 구하는 공식은 아래와 같다.
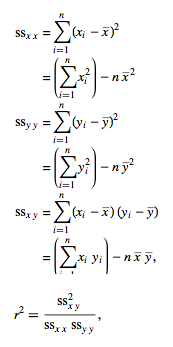
수식 참고 : http://mathworld.wolfram.com/LeastSquaresFitting.html
이 값은 완벽하게 맞아 떨어질수록 1에 가까워진다. 위의 python 돌린 그림을 보면 correlation coefficient가 0.99996가 나왔는데 1과 아주 가까우므로 매우 훌륭하게 fit하고 있다고 볼 수 있다. Python에서 best-fit을 구하여 dataset과 같이 보면 아래와 같다.
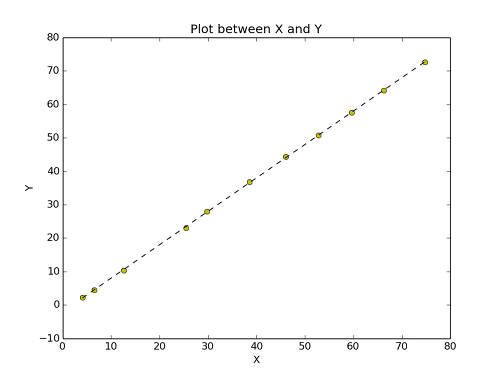
점선으로 표시된 선이 우리가 구한 Best-fit이며 y = 0.9992x - 2.0007 의 그래프이다.
linear regression에 대해서 포스팅은 여기서 마치려고 한다. 다음 포스팅은 multi linear regression이다. 기본적으로 linear regression이지만, 2개가 아닌 여러 개의 attribute을 통해 linear regression을 알아볼 예정이다.