[Data Mining] Logistic Regression
Logistic Regression을 공부해보자. 참 이것 때문에 시간을 좀 많이 쓰긴 했따. 나는 하나하나 일일이 손으로도 할 수 있을 정도의 디테일을 원하는데 그 정도의 디테일을 설명해둔 곳이 별로 없어서... 찾고 공부하고 찾고 하느라 못 했다. 아무튼 지금 글을 쓰고 있다는 것은 알긴 알았다는 것!
여기서 설명하고 있는 Logistic Regression은 실제 Python이나 R 등에서 구현되어있는 Logistic Regression과는 약간 차이가 있다. 이유는 이 글 마지막에 설명하겠다. 그래도 기본 원리는 이와 같으니 기본 원리를 이해하고 싶은 사람들은 읽어보면 좋다.
우선 Logistic Regression은 특정 attribute들을 통해서 0 또는 1을(yes or no) 구분하기 위한 방법이다. 예를 들어, 사람들의 구매 패턴을 분석하여 어떤 사람이 지금 이 물건을 살까 말까(0 또는 1)를 추측하거나, 사람들의 건강 상태를 분석하여 그 사람이 앞으로 10년 이상 더 살까 말까(0 또는 1)를 추측하는 것이다. 기본적으로 binary attribute이 하나 있어야 된다는 뜻이다.
이것들을 정확하게 추측할 수는 없다. 여기서 우리는 확률의 개념을 사용한다. 그 확률은 조건부 확률이다. X가 어떤 값으로 주어졌을 때, y가 1일 확률을 구하여라. 예전 고등학교때 많이 봤었던 그 조건부 확률이다. P(Y=1|X=n)로 나타낸다. 확률을 계산하는 문제에서 기존의 linear regression은 문제가 발생한다. 당연히 확률은 0과 1 사이의 값을 가져야 하는데 linear regression로는 그 boundary를 정할 수가 없다. 여기서 우리는 확률 p를 조금 변형시킬 것이다. 우선은 p/(1-p)로 변형시키자. 이런 것을 odds라고 하는데 이렇게 변형시키면 아래와 같이 된다.
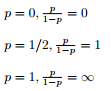
이게 무슨 의미일까. 아직은 별 의미를 못 찾겠다. 그런데 여기에 log를 씌우면 뭔가 새로운 의미가 부여된다.
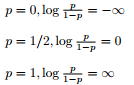
log를 씌우니까 p=0일때는 -무한대, p=1일때는 +무한대를 갖게 된다. p가 0과 1일 때가 균형을 갖게 된다. log를 씌운 이 함수를 우리는 logit function이라고 부르고 이 값이 x와 linear regression을 이루게 된다. 따라서 아래와 같은 식을 세울 수 있게 된다.

여기서 중요한 점이 하나 있는데, x가 1 증가할 때마다 log(p/(1-p))는 a만큼 증가한다는 것이다. 당연한 말이다. 당연한 말인데 logistic regression에서는 아주 중요한 내용으로 꼭 언급되고 넘어가는 부분이다. 아마도 log(p/(1-p))가 x와 linear regression을 이룬다는 점을 강조하기 위함이 아닌가 싶다. 아무튼 이 식을 p에 대해서 나타내고 p와 x의 관계를 그래프로 나타내보자.


그림 출처 : http://artint.info/html/ArtInt_180.html
위의 그림에서 x가 ax+b라는 것을 감안하고 보자. 아무튼 그래프를 보니 이제 뭔가 좀 그럴듯하다. 확률이니까 0과 1사이의 값을 갖되 x는 모든 값이 가능하게 되는 그림이다. (그림에서는 x값이 -10에서 10사이인데, 사실은 +,- 무한대로 뻗어 나갈 수 있다)
실제로 어떤 식으로 적용되는지 확인해보자. 이 데이터는 사람의 나이에 따라서 어떤 값이 yes 또는 no로 주어지는 데이터이다. 다운로드 한 data를 보면 아래와 같다.(data 첨부)
 logistic.data
logistic.data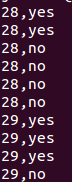
data source : http://vassarstats.net/logreg1.html
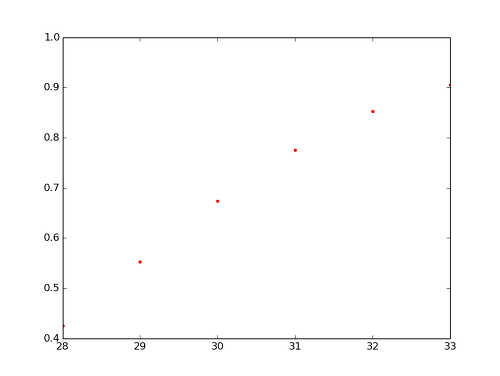
나이를 x로 놓고 조건부 확률 및 필요한 값들을 구해보면 아래와 같다

여기서 ln(odds)와 x는 linear regression 관계를 이룬다. 우리가 이전 포스팅에서 공부했었던 linear regression 구하는 방법으로 x와 ln(odds)의 best-fit line을 구하면 된다. 이 때 고려해야할 것은 data의 개수 인데, 예를 들어, 28의 ln(odds)는 -0.6931인데 이것이 6개 있다. 마찬가지로 29의 ln(odds)는 -0.4055인데 이것이 5개 있다. 이런식으로 33까지 개수를 센 후 linear regression을 통해 best-fit line을 구하면 아래와 같은 결과를 갖게 된다.

자 여기서 python을 통해 실제 logistic regression을 구해보고 결과를 보도록 하자.

coefficient와 intercept를 비교해보면 값이 얼추 비슷하기는 하나 다른 것을 알 수 있다. 왜 그럴까? python에서는 maximum likelihood estimation이라는 방법을 통해 구현했기 때문이다. 솔직히 maximum likelihood estimation가 뭔지는 잘 모르겠다. 이 부분은 나중에 다시 한번 공부해보도록 하자.
그리고 사실 이번 data는 사이즈가 너무 작아서 sigmoid function 그래프 모양이 잘 나오지 않았다. 그래서 조금 더 큰 data로 위와 똑같은 일을 하면 아래와 같은 그림이 나오게 된다.

자 이제 Logistic Regression을 마치는데 다음 포스팅 소개와 더불어 한 가지만 더 말해보자. Logistic Regression으로 우리는 binary attribute에 대한 확률을 구했다. 사실 이것은 (다음에 포스팅할) classification과 더욱 가까운 개념이다. 사실 그래서 Logistic Regression은 사람에 따라 classification model로 분류하는 사람들도 있다. 다음 포스팅부터는 classification을 자세히 공부해보자.
p.s. 아주 맘에 드는 포스팅은 아니지만, 공부하면서 가장 어렵다고 느낀 부분이었는데, 그래도 가장 기본이 되는 원리는 설명했으니 그나마 다행이다.