최근에 읽은 논문 하나 요약해보려고 한다. 바로 Universial Language Model Fine-Tuning, ULMFiT이다. 우선, 논문을 단 한 줄로 요약하자면,
"어떤 NLP 테스크 A를 수행할 때, 그것을 처음부터 학습하지 말고, 언어의 속성을 학습해둔 language model L을 먼저 학습 후, 그것을 가지고 A 테스크를 진행하면 훨씬 더 적은 데이터로 state-of-art 수준 이상의 결과를 빠르게 얻을 수 있다."
아이고, 어렵다. 본격적으로 설명을 하기 전에 조금 만 더 풀어서 설명해보자.
예를 들어, 어떤 영화의 리뷰가 긍정적인 리뷰인지 부정적인 리뷰인지를 1 또는 0으로 구분하는 모델을 만든다고 하자. 일반적으로 이것을 하기 위해 영화 리뷰 데이터 모아서 전처리하고 전처리된 것을 모델에 입력하는데, 이 모델은 조금도 학습되어 있지 않은 Scratch에서부터 시작한다. 즉, 각 레이어에서 사용되는 weight들이 랜덤으로 초기화된 상태에서 시작하게 된다. 이렇게 하는 것보다 더 좋은 방법이 있다는 것을 알려주기 위한 논문이 바로 ULMFit이다.
그래서 어떻게 하느냐? 우선 무턱대고 영화 리뷰 데이터를 가져오지 말고, 여러가지 텍스트 데이터를 끓어와라!! 자연어라면 끓어와라!! 자연어 데이터라고 하면, 이메일 데이터일 수도 있을 것이고, 뉴스 데이터일 수도 있을 것이고, 소설 데이터일 수도 있을 것이다. 아무튼 자연어 데이터를 가져와라. 이 데이터는 레이블링도 필요 없다. Language Model은 주어진 단어들 이후에 그 다음 단어가 어떤 단어가 나오는지를 학습하는 유형의 모델이기 때문에 0, 1의 레이블링은 필요 없다. 아직 어떻게 만드는지는 설명하지 않지만, 어쨌든 이렇게 가지고 온 자연어 데이터를 이용해서 Language Model을 우선 만들어 놔라(pre-train해라)
Language Model을 만든 후, 그 학습된 모델을 그대로 로딩해서, 그 다음부터 영화 리뷰 데이터를 이용해서 Language Model을 Tuning하고 classifier를 학습하라는 것이다. 즉 학습을 "from scratch"부터 하지 말고, "from pre-trained"부터 시작하라는 것이다. 이렇게 하면, 기본적인 언어의 속성은 이미 가지고 있는 상태에서 시작하기 때문에 만들고자 하는 '영화 리뷰 분류' 관련된 데이터가 적더라도 학습이 오버피팅되지 않고 잘 된다는 것이다. 그림으로 한번 보고 본격적으로 이 논문을 파보도록 하자.
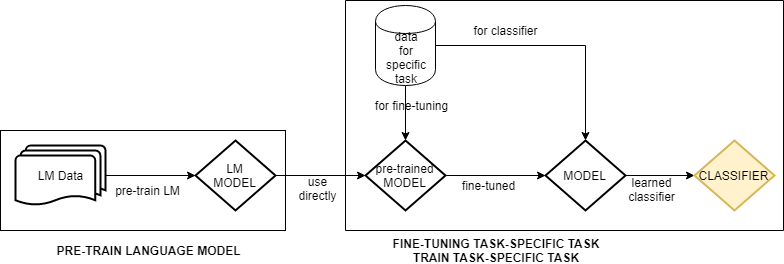
1. Train Language Model(LM)
LM 학습하는 것에 대해서 이야기해보자. 사실 이 논문에서 LM의 구조를 자세히 다루지 않았다. 이들도 다른 논문에서 소개된 LM을 사용했다고 한다.
"In our experiments, we use the state-of-theart language model AWD-LSTM (Merity et al., 2017a), a regular LSTM (with no attention, short-cut connections, or other sophisticated additions) with various tuned dropout hyperparameters"
AWD-LSTM이라는 state-of-art LM을 사용했다고 한다. 논문에서는 이 부분을 "General-domain LM pretraining"이라는 소제목으로 설명했는데, 여기서 기학습된 LM을 사용하는 것에 대한 실질적인 장점을 설명하고 있다.
"Pretraining is most beneficial for tasks with small datasets and enables generalization even with 100 labeled examples"
기학습된 LM을 사용하면 레이블링된 데이터가 100개만 있어도 generalization 즉 일반화된 모델을 만들어낼 수 있다는 것이다. "오버피팅을 피할 수 있다"와 같은 말이다. 이건 정말 대단하다고 생각한다. 실무에서 겪는 가장 큰 문제점이 무엇일까? 데이터는 많은데 실제로 레이블링된 것이 없어서 분석가가 데이터를 한개씩 레이블링 하거나 모델 만들기를 포기하거나 등등 좋지 않은 일이 벌어진다. 그러지 않아도 된다는 것이다. 100개는 너무 실험치 숫자라고 쳐도, 500~1000개정도는 레이블링 하는 것이 크게 소모적인 일이 아니라고 생각한다.
자, 그럼 LM을 학습하는 방법은 무엇이냐? 일반적으로 LM을 학습시킨다고 함은, 주어진 단어의 다음 단어를 예측하는 모델을 만든다는 것이다. 즉,
"학교 종이 땡땡땡 어서" ???
???는 무엇일까? "모이자"이다. "학교 종이 땡땡땡 어서"라는 데이터로부터 "모이자"라는 타겟을 예측하는 모델을 만드는 것이 기본적인 LM의 학습 방법이다. Word2Vec등도 LM의 일부인데, 이러한 모델도 CBOW형태나 Skipgram형태 모두 하나의 단어로부터 주변 단어를 예측하는 방식의 모델이다. 복습 차원에서 살짝 정리해보자면,
- CBOW: 주변 단어로부터 하나의 단어를 예측하는 모델
- Skipgram: 하나의 단어를 통해서 주변 단어를 예측하는 모델
그러하다.
아무튼 LM을 학습한다라는 뜻은 주어진 단어들을 이용해서 다른 단어를 예측하는 것을 학습하겠다는 의미이다. 그것을 위한 알고리즘으로 AWD-LSTM이라는 모델을 사용해서 LM을 학습했다는 것이다. AWD-LSTM은 다음 논문 리뷰에서 자세하게 다루려고 한다.
2. Target task LM fine-tuning
논문에서는 다음과 같이 말을 시작하고 있다.
"No matter how diverse the general-domain data used for pretraining is, the data of the target task will likely come from a different distribution"
아무리 기학습에 사용된 모델이 다양하다고 한들, 우리가 최종적으로 학습할 테스크 데이터는 완전히 다른 분포로부터 왔다는 것이다. 그래서 어느 정도의 튜닝이 필요하다는 것이다. 쉽게 말해서, 아무리 벤츠가 자동차를 잘 만든다고 한들 F1에 나가려면 약간의 튜닝은 해야된다. 대신 시골 경운기 모터로 우여곡절 끝에 만든 자동차를 F1용으로 튜닝하는 것보다는 벤츠를 가지고 F1용으로 튜닝하는 것이 훨씬 더 빠르고 성능도 좋지 않을까? 그런 개념이다. 그래서 target task에 대한 fine-tuning은 어떤 방법으로 할까? 두가지 타입이 있다. discrimitive fine-tuning과 slanted triangular learning rate이다. 어려운 개념은 아니므로 아래에 살짝 정리만 해두려고 한다.
- discrimitive fine-tuning: AWD-LSTM 모델의 각 LSTM 계층마다(layer) 서로 다른 learning rate을 적용하는 기법이다.

위의 식에서 l은 각각의 레이어이다. 즉, 현재 t의 파라미터 중에서 l번째 파라미터는 t-1에서의 l번째 파라미터에 어떤 숫자를 빼주면 되는데, 그 숫자는 l번째 레이어에 대한 learning rate x 파라미터의 변화량이다.
- slanted triangular learning rate: 모델의 learning rate을 삼각형 모형으로 올렸다가 내리는 것이다. 그 공식은 아래와 같다.

위의 식에서 사용된 변수는 각각 아래와 같은 의미를 갖는다.
T: 학습시 iteration 횟수
cut_frac: (learning rate을 줄이기 시작하는 iteration)/(전체 iteration(T))
p: learning rate을 증가 혹은 감소시키는 비율
ratio: 가장 적은 learning rate과 maximum learning rate의(ηmax) 비율
ηt: t번째 iteration에서의 learning rate
이 값들을 아래와 같이 설정해서 사용했다고 한다.
frac = 0.1
ratio = 32
ηmax = 0.01.
3. Target task classifier fine-tuning
classifier를 fine-tuning하는 부분이다.
"Finally, for fine-tuning the classifier, we augment the pretrained language model with two additional linear blocks. Following standard practice for CV classifiers, each block uses batch normalization (Ioffe and Szegedy, 2015) and dropout, with ReLU activations for the intermediate layer and a softmax activation that outputs a probability distribution over target classes at the last layer."
classifier를 fine-tuning하기 위해서 두 개의 리니어 블락을 변형?하겠다는(augment) 것이다. 그 구조는 다음과 같다.
- 두번째 마지막 블록: batch normalization + ReLU activation
- 확률 값을 생성하는 마지막 블록: dropout + softmax activation
그리고 논문에 이렇게 나온다.
"As input documents can consist of hundreds of words, information may get lost if we only consider the last hidden state of the model."(이부분 영어...)
입력으로 들어오는 텍스트 데이터의 단어가 매우 많기 때문에 모델의 마지막 hidden state만 고려한다면 정보 손실이 일어날 수 있다. 이 문제를 해결하기 위해서 이 논문에서는 h1 ~ hm을 meanpool, maxpool한 후 concatenate했다고 한다.
"For this reason, we concatenate the hidden state at the last time step hT ofthedocumentwithboththemax-pooledandthe mean-pooled representation of the hidden states over as many time steps as fit in GPU memory H = {h1,...,hT}: "
[공식]
이 부분이 처음부터 학습을 시작하는(from scratch) 유일한 layer이다. 이 부분에서 너무 공격적으로 학습하면 모델이 전에 학습해둔 정보를 잃게 되고(catestrophic forgetting), 너무 조심스럽게 학습하면 수렴하는 것이 늦어진다.
ULMFiT에 대한 기술적인 내용은 여기까지이다. 여기까지 개념 설명을 끝내고 ULMFiT의 효과를 검증하는 분석을 해보자.
4. Analysis
분석 단계에서 몇몇 유명한 NLP 데이터를 사용했다고 한다. IMDb, TREC-6, AG 등이다.
4.1 pre-training의 효과 검증
우선 pre-training VS without pre-training training 결과를 보자.

(validation error rate 기준)
pretraining하는 것이 결과가 훨씬 좋다. 좋은 것도 좋은 것이지만 결과가 꽤나 일정하다. (개인적으로 pretraining보다 일정한 결과를 낸다는 분석 결과에 더 관심이 간다.)
4.2 language model의 효과 검증
ULMFiT을 한 것과 일반적인 LM을 만든 것을 비교한 부분이다. 즉 pretraining 알고리즘 자체에 대한 효과성 검증이다.

일반적인 LM을 뭘로 했는지는 모르겠다. 결과를 보면 테이블4에서의 pretraining 안 한것보다는 일반적인 LM이 더 좋기는 한데 ULMFiT보다는 별로다.
4.3 fine-tuning의 효과 검증

Full: fine-tuning을 전체 레이어에 대해서 적용
Last: fine-tuning을 마지막 레이어에 대해서만 적용
Freez: gradual unfreezing, 마지막 classification 레이어부터 시작해서 점점 위 레이어로 올라가면서 레이어의 파라미터를 unfreezing하는 것. unfreezing한다는 것은 학습돼 있는 파라미터가 변할 수 있도록 fine-tuning한다는 것이다.
Disc: discriminative fine-tuning
Stlr: slanted triangular learning rate
Cos: aggressive cosine anealing schedule, Freez에 대해서만 수행함
가장 좋은 결과를 내는 것은 Freez + disc + stlr이다. 3개의 데이터 중 2개의 데이터에서 최고 성능을 보이고, 나머지 하나에서도 두번째로 놓은 결과를 보여주고 있다.
4.4 fine-tuning 진행과정
fine-tuning이 진행되면서 error rate이 어떻게 변화하는지 알아보기 위한 분석이다. 아래의 그림과 같다.

위에서부터 차례대로 IMDb, TREC-6, AG인데 ULMFiT에 해당하는 노란색 선들은 비교적 안정적이고 시간이 지나면 지날수록 error rate도 작아지는 방향으로 간다. (흠, 마지막 AG에 대해서는 조금 애매하긴하다..)
ULMFiT의 논문 리뷰는 여기서 마치려고 한다. 다음 논문 리뷰는 AWD-LSTM로 하려고 한다.