ViTCoD: Vision Transformer Acceleration via Dedicated Algorithm and Accelerator Co-Design
Deep Learning 2023. 1. 14. 02:28이번 논문은 ViT를 가속화하는 기법을 소개하는 논문이다. 우선 ViT는 Vision Transformer이다. NLP에서 Self Attention을 이용한 Transformer가 비약적인 성능 향상을 가져왔고, 그 구조를 Vision 영역에 맞게 고친 것이 ViT이다. ViT에 대해서 자세하게 설명해둔 글이 있는데 조만간 업로드하려고 한다.
트랜스포머 구조의 가장 큰 문제점은 Self Attention 연산 속도가 매우 느리다는 것이다. 논문에서는 ViT의 트랜스포머 구조는 사실 NLP의 트랜스포머보다 가속화하기에 유리하다고 설명하고 있다. 그 이유는 ① ViT는 고정된 사이즈의 입력 토큰이라는 것과 ② ViT 어탠션의 90% 이상은 sparse한 패턴이기 때문이다. 이제 어떻게 ViT의 Self Attention을 가속화 했는지 자세하게 알아보자.
1. divide-and-conquer 알고리즘
ViT 어탠션의 90% 이상은 sparse한 패턴이다. 어탠션 연산은 matrix multiplication을 통해 계산되는데 이렇게 연산한 효과가 그렇게 크지 않는 부분, 즉 어탠션 연산의 효과가 미비한 부분의 weight은 0으로 치환해서 matrix 자체를 sparse하게 바꿀 수 있다. 성능을 크게 회손하지 않는 범위 내에서 matrix 자체를 sparse하게 바꿔도 무방하다는 것이다.
그러면 성능을 크게 회손하지 않는다는 것을 어떤 기준으로 판단할까? 논문에는 아래와 같이 알고리즘이 기술돼 있다.

2번 줄에 보면 어떤 임계치 값을 정해두고 그 임계치를 넘지 않을 때까지 계속해서 인덱스를 기록해두고 그 인덱스에 해당하는 부분만을 사용하도록 하게 한다.
이렇게 어탠션의 weight 값을 임계치 기반으로 sparse하게 바꾼 후에 reordering을 한다. sparse한 부분과 dense한 부분으로 나누는 것이다. 나눈 후에 어탠션 값을 plotting 하면 아래와 같은 패턴으로 보여진다. ViT의 입력 토큰이 고정적이기 때문에 NLP의 트랜스포머에 비하여 가속화하기에 유리하다고 말했는데, 그 이유를 여기에서 조금 설명할 수 있다. sparse한 부분과 dense한 부분의 비율이 어느 정도 고정적으로 정해질 수 있기 때문에 가속기를 하드웨어적으로 구현할 때 PE(Processing Elements)의 워크로드 사이즈를 어느 정도 정할 수 있다고 한다.
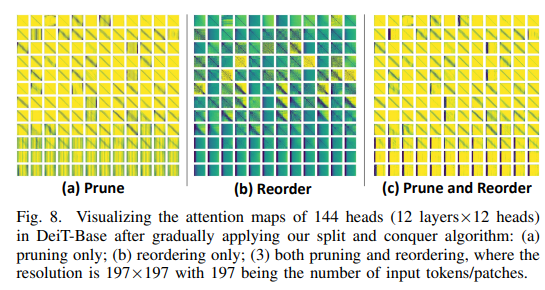
dense한 부분의 연산은 일반적인 행렬연산(GEMM)이므로 이는 병렬로 처리하면 빠르게 할 수 있다. sparse한 부분의 연산은 sparse matrix multiplication을 수행하면 된다. 이는 sparse한 인덱스를 따로 테이블로 가지고 있어서 그 부분에 대해서만 연산을 수행하면 되므로 훨씬 적은 양의 곱셈 연산으로 원하는 결과를 얻을 수 있다.
2. 하드웨어 가속기
소프트웨어만을 다루는 사람으로서 이해하기가 조금 힘든 영역이었다. 그래도 조금 어설프게나마 이해한 부분을 정리해보자. divide and conquer를 통해서 구분한 sparse/dense한 영역을 계산하기 위해서 따로 하드웨어 모듈을 만들었다고 한다. 아래의 그림에서 sparser engine과 denser engine이 바로 그 부분이다.
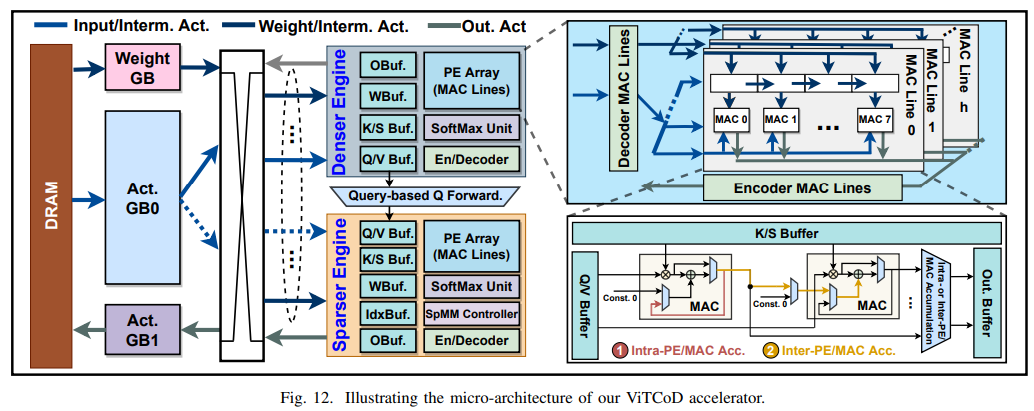
위 그림에서 PE Array라고 하는 부분을 잠깐 설명해보자. neural network accelerator에서 핵심 연산은 곱셈과 덧셈(MAC)이다. MAC을 레지스터, 메모리와 함께 어떻게 잘 패킹하는지가 neural network accelerator를 디자인하는데 중요한 부분이다. MAC, 레지스터, 메모리를 함께 패킹해둔 것이 하나의 PE라고 하고 이것을 여러 개 연결해둔 것이 PE Array이다.
다시 VitCoD 논문으로 돌아와보자. 위 그림을 보면 denser engine 부분과 sparser engine의 버퍼 구조가 조금 다르다. denser engine은 딱히 특별한 것 없이 일반적인 행렬 곱셈(GEMM)을 수행하면 되고, sparser engine은 sparse matrix multiplication을 수행하기 위해 IdxBuf 등이 추가적으로 필요하다. sparse matrix multiplication은 행렬 자체가 sparse하기 때문에 non-zero 부분만 연산을 하면 되고 그 non-zero 인덱스를 가지고 있기 위한 버퍼가 IdxBuf이다.
실제 칩의 그림을 보면 위와 같다고 한다.
3. Auto Encoder/Decoder 모듈
어탠션 값을 sparse/dense한 부분으로 나누고 이를 위한 각각의 하드웨어 가속기를 만들었으니 이제 빨라졌겠네. 라고 생각하면 오산이다. 위 그림에서 sparse/denser engine 전까지의 연산은 Q, K를 만들때까지이다. sparser/denser engine은 Q, K 값이 나오기 전까지는 사용되지 않는다는 것이다. 그러면 Q, K를 만들고 그 값을 sparser/denser engine으로 값을 이동시켜야 하는데, 그 과정에서 발생하는 overhead가 엄청나다. 이 overhead를 줄이기 위해서 Auto encoder/decoder 모듈을 사용한다. Q, K 값을 auto-encoder로 압축해서 작게 만든 후 sparser/denser engine으로 이동시키고, 이동시킨 후에 decoder를 통해서 다시 Q', K'를 만들어서 그 값으로 이 후 연산을 진행하게 된다. Auto Encoder/Decoder 모듈을 통해서 데이터 이동 시간을 줄이므로 인해서 sparser/denser engine의 사용율이 높아지게 된다.
4. 결과
ViTCoD를 적용한 결과 전체적인 연산의 속도는 아래와 같이 개선됐다.
| speed-up | CPU | Edge-GPU | GPU Platform |
| Attention Only | x 235 | x 160 | x 86.0 |
| Overall | x 33 | x 5 | NaN |
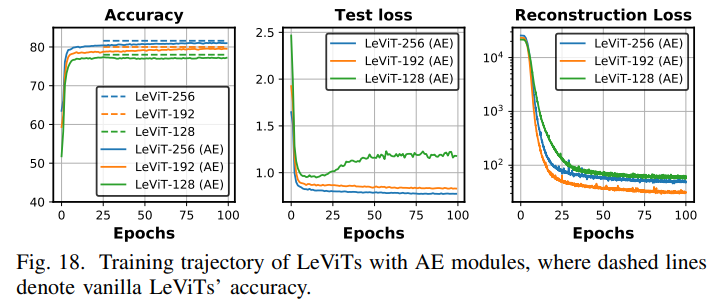
또한 AE 모듈을 삽입한 부분을 보면 AE를 삽입했음에도 불구하고 정확도 측면에서는 거의 차이가 나지 않는다는 것을 알 수 있다.
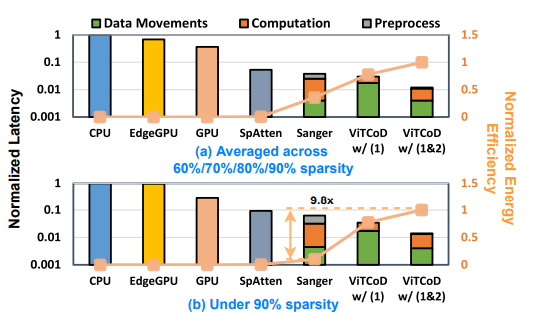
AE를 삽입함으로서 Data Movements 비용도 절반으로 줄어들었다. 아래의 그림을 보면 Sanger에 비해서 ViTCoD(1)은 Data Movements 비용이 상당히 높지만, ViTCoD(2)는 Data Movements 비용이 훨씬 낮아진 것을 확인할 수 있다. 또한 Computation 비용도 ViTCoD가 훨씬 낮아졌다.
이번에 ViTCoD 논문을 리뷰하면서 SW를 하는 사람으로서 HW의 벽을 실감할 수 있었다. 2번 하드웨어 가속기 부분을 정말 이해하기 힘들더라. 조금씩 조금씩 하나 하나 이해하다보면 빨라지겠지..?
'Deep Learning' 카테고리의 다른 글
| TVM: An Automated End-to-End Optimizing Compiler for Deep Learning (0) | 2022.12.07 |
|---|---|
| welcome back ! (1) | 2022.12.07 |
| [Deep Learning] Activation Function (0) | 2019.05.08 |
| 시작하며 (0) | 2019.05.08 |
| [Deep Learning] Convolutional Neural Network (4) | 2017.06.10 |



